







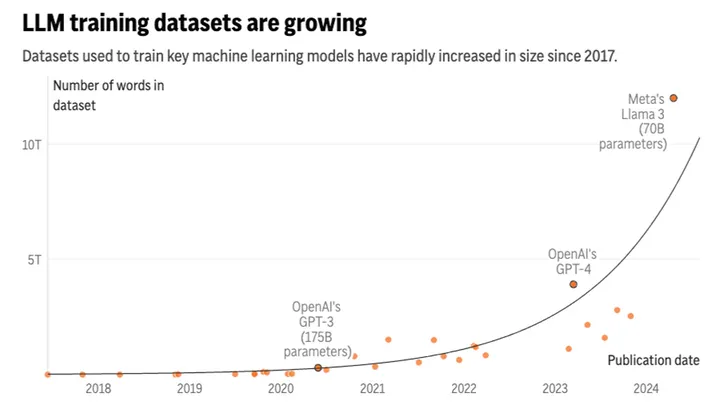
По прогнозам, разработчики искусственного интеллекта могут столкнуться с дефицитом доступных текстов для обучения уже в период с 2026 по 2032 год. Исследование, проведенное группой Epoch AI, показало, что компании могут исчерпать запасы публичных данных, используемых для тренировки моделей ИИ, уже в ближайшие годы.
На данный момент системы ИИ, подобные ChatGPT, обучаются на триллионах слов, написанных людьми и доступных в интернете. Эти данные включают не только литературные произведения, но и комментарии на социальных платформах. Однако с исчерпанием этих ресурсов разработчикам придется искать альтернативные источники данных.
Тамай Бесироглу, один из авторов исследования, сравнил эту ситуацию с “золотой лихорадкой”, когда ресурсы исчерпываются слишком быстро. Он подчеркнул, что в ближайшие годы крупные технологические компании, такие как OpenAI и Google, будут стремиться к заключению сделок для доступа к высококачественным и общественным источникам данных, таким как форумы Reddit и новостные медиа.
В долгосрочной перспективе этих ресурсов будет недостаточно, что заставит компании использовать личные данные, электронные письма или же текстовые сообщения, либо начать использование менее надежных “синтетических данных”, созданных другими ИИ-моделями. Бесироглу отметил: “Существует серьезная проблема с ограничением количества данных. Если мы исчерпаем их, развитие ИИ станет менее эффективным”.
Исследование также указывает на то, что за последние годы были разработаны новые методы, которые позволяют эффективнее использовать уже существующие данные. Однако, несмотря на эти улучшения, ученые прогнозируют, что к середине 2020-х годов запас текстов, доступных для обучения ИИ, может быть исчерпан.
Результаты исследования будут представлены на Международной конференции по машинному обучению в Вене, Австрия, этим летом. Epoch AI – это некоммерческий институт, финансируемый сторонниками движения за эффективный альтруизм, направленный на снижение рисков, связанных с ИИ.
Присоединяйтесь к нашему телеграм-каналуНиколас Папернот, доцент инженерии Университета Торонто и исследователь некоммерческого Института векторного интеллекта, выразил сомнения по поводу необходимости постоянного увеличения масштабов моделей ИИ. Он отметил, что обучение более специализированных моделей для выполнения конкретных задач также может быть эффективным для развития ИИ.
OpenAI уже проводит эксперименты с созданием большого объема синтетических данных, но Папернот предупреждает, что обучение языковых моделей искусственного интеллекта на собственных данных может привести к “коллапсу”, когда качество выходных данных ухудшается.
Исследование отмечает, что платить людям за создание текстов для обучения ИИ не является экономически эффективным решением. OpenAI уже проводит эксперименты с созданием большого объема синтетических данных, но использование таких данных также вызывает сомнения.
Селена Декельманн, главный продуктовый и технический директор Wikimedia Foundation, выразила надежду, что будут созданы стимулы для людей продолжать вносить вклад в Wikipedia. Она также отметила, что компании ИИ должны беспокоиться о том, как сохранять и обеспечивать доступность контента, созданного людьми.
Разработка ИИ будет сталкиваться с новыми вызовами по мере исчерпания доступных данных, по мнению исследователей. В ближайшее время компании будут платить за доступ к качественным данным, но в будущем им придется искать новые методы и подходы для продолжения развития ИИ.





